|
Size: 5167
Comment: Move cheat sheet to "see also" section
|
Size: 5828
Comment: Add an example to calculate relative performance of compiled patterns
|
| Deletions are marked like this. | Additions are marked like this. |
| Line 61: | Line 61: |
| I don't know how much faster compiled forms are than non-compiled forms. | The relative speed of compiled versus non-compiled patterns can be shown using the timeit module: {{{ python -m timeit -s 'import re' \ 'match_obj = re.match("<(.*?)>(.*?)</(.*?)>", "<h1>robot</h1>")' 1000000 loops, best of 3: 1.35 usec per loop python -m timeit -s 'import re ; match_re = re.compile("<(.*?)>(.*?)</(.*?)>")' \ 'match_obj = match_re.match("<h1>robot</h1>")' 1000000 loops, best of 3: 0.572 usec per loop }}} The above numbers were produced on an Intel Core i7 3770k running Python 2.7.6 (circa 2014). You should run the above commands on your Python version and specific hardware, and use patterns that represent your problem domain, for more representative results. |
| Line 107: | Line 119: |
| Line 118: | Line 130: |
| ---- CategoryDocumentation |

flags when compiling:

(All images PD, released by author, LionKimbro.)
Searching & Matching
You can search or match.
search -- find something anywhere in the string, and return it
match -- find something from the beginning of the string, and return it
You can also split on a pattern.
For example:
...which produces:
["This is a ", "((test))", " of the ", "((emergency broadcasting station.))" ]
Compiling
If you use a regex a lot, compile it first.
Consider:
...which outputs: ('h1', 'robot', 'h1')
If you were going to do that match a lot, you could compile it, like so:
...which yields the same result.
The relative speed of compiled versus non-compiled patterns can be shown using the timeit module:
python -m timeit -s 'import re' \
'match_obj = re.match("<(.*?)>(.*?)</(.*?)>", "<h1>robot</h1>")'
1000000 loops, best of 3: 1.35 usec per loop
python -m timeit -s 'import re ; match_re = re.compile("<(.*?)>(.*?)</(.*?)>")' \
'match_obj = match_re.match("<h1>robot</h1>")'
1000000 loops, best of 3: 0.572 usec per loopThe above numbers were produced on an Intel Core i7 3770k running Python 2.7.6 (circa 2014). You should run the above commands on your Python version and specific hardware, and use patterns that represent your problem domain, for more representative results.
See Also
Regular Expression HOWTO - excellent Python-based regular expression tutorial, by A.M. Kuchling.
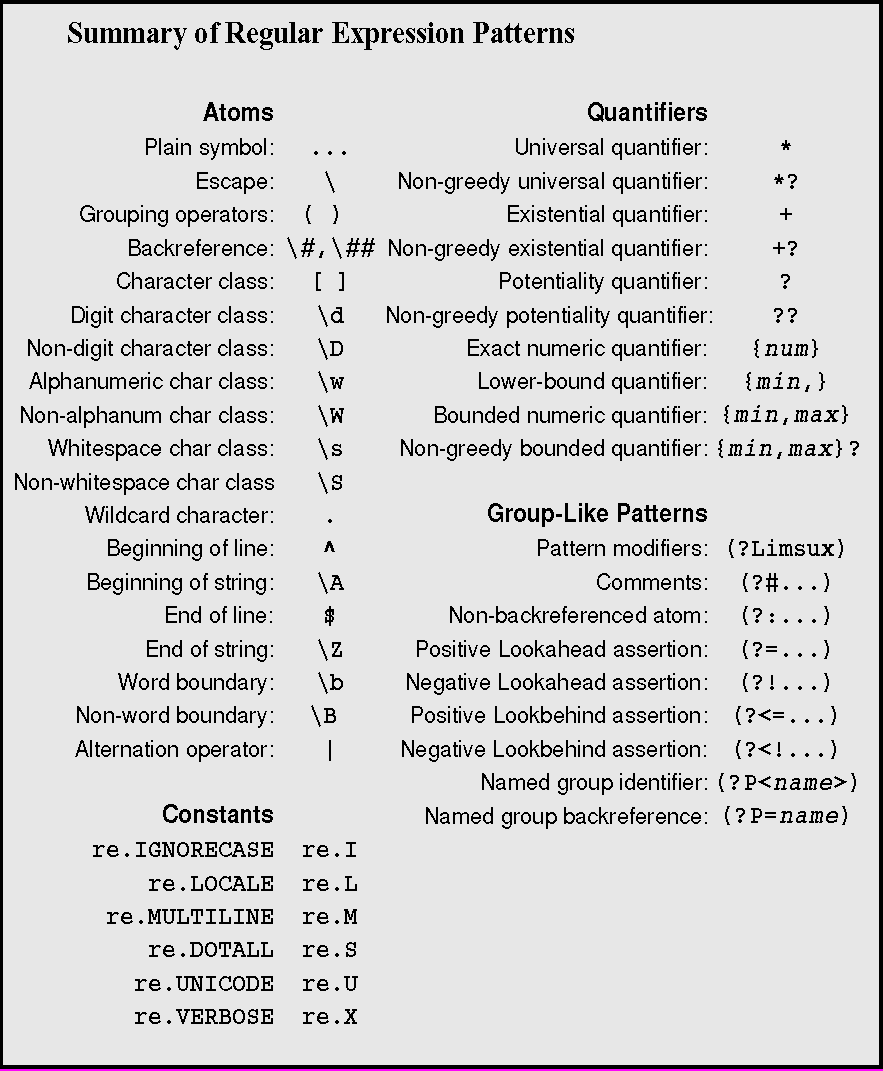
Regex in a Nutshell cheat sheet
RegexBuddy - Handy tool to create and test Python regular expressions
redemo tool -- ships with Python (C:\\Python24\Tools\Scripts\redemo.py), indispensible when trying out regular expressions; ships with PythonCard as well
periodic table of PERL operators -- for those who like visualization
{kind=link}
{kind=link}
{kind=link}
Discussion
Requests
documentation on using re with Unicode ..?
Problem?
The following feature does not seems to work in python:
For example, the ICU regular expression provides the following patterns:
- \N{UNICODE CHARACTER NAME} Correspond au caractère nommé
- \p{UNICODE PROPERTY NAME} Correspond au carctère doté de la propriété Unicode spécifiée.
- \P{UNICODE PROPERTY NAME} Correspond au carctère non doté de la propriété Unicode spécifiée.
- \s Correspond à un caractère séparateur. un séparateur est définit comme [\t\n\f\r\p{Z}].
- \uhhhh Correspond à un caractère dont la valeur hexa est hhhh.
- \Uhhhhhhhh Correspond à un caractère dont la valeur hexa est hhhhhhhh. Exactement huit chiffres héxa doivent être fournis, même si le code point unicode le plus grand est \U0010ffff.
-- anonymous
I don't understand the problem. -- LionKimbro 2006-03-25 16:31:35
Visualization
I like the Venn diagram in this image. However, one part of the image is confusing. Where it refers to python strings, and "regex strings" (which are actually Python "raw" strings) and something called "match strings" ... what are these "match strings. -- JimD 2004-12-30 20:03:54
The image isn't meant to be explanatory, it is meant to be reference and refreshing material.
That said: The "match string" is the final product of either of the two above expressions. It is what the above two expressions will literally match. If you have a better phrase, or would like to correct "raw" to "regex," feel free to download the SVG, edit the text, place an image on the web, and link it from here. (The damn LongImageIncorporationProcess strikes again.) I may eventually get around to it myself one day, but it seems there are higher priorities, and the diagram is "good enough."
That said, I appreciate the correction. -- LionKimbro 2005-01-01 00:22:14
Image Hosting
At the top of this page were two images/scehmes about re. Is it possible to redraw them here somehow? That server is not working, maybe someone has them dowloaded locally. Thanks a lot. -- PavelKosina
I've uploaded one as an attachment, still need to upload the other... And, the source...
(Anyone can do this, though, when the computers are online.)
-- LionKimbro 2006-03-25 16:31:35